Optical Character Recognition. Al jarenlang wordt mensen de belofte verteld dat het allemaal zo handig is. Je pakt een boek uit de bibliotheek, legt het op je scanner en binnen 10 seconden krijg je dezelfde tekst als Word documentje gepresenteerd. De meeste scanners krijgen ook gratis OCR software meegeleverd. Na installatie blijkt alleen dat de software tot hooguit 95% nauwkeurig is. Je bent dan ook vaak langer bezig met het verbeteren van fouten dan dat je tijdswinst hebt met het inscannen ten opzichte van alles zelf overtypen.
Met handgeschreven teksten is het helemaal aanknoeien. Er zíjn wel een paar OCR applicaties die handgeschreven tekst aankunnen, maar daarvoor moet je vaak extra groot schrijven, precies dezelfde letters en streepjes gebruiken en je moet ze vaak dagen lang “trainen” om je handschrift te herkennen. Omdat ik vaak dingen bedenk die ik uitgetypt op de computer wil hebben terwijl ik geen computer bij me in de buurt heb, heb ik mijn eigen OCR engine voor handgeschreven tekst ontworpen.
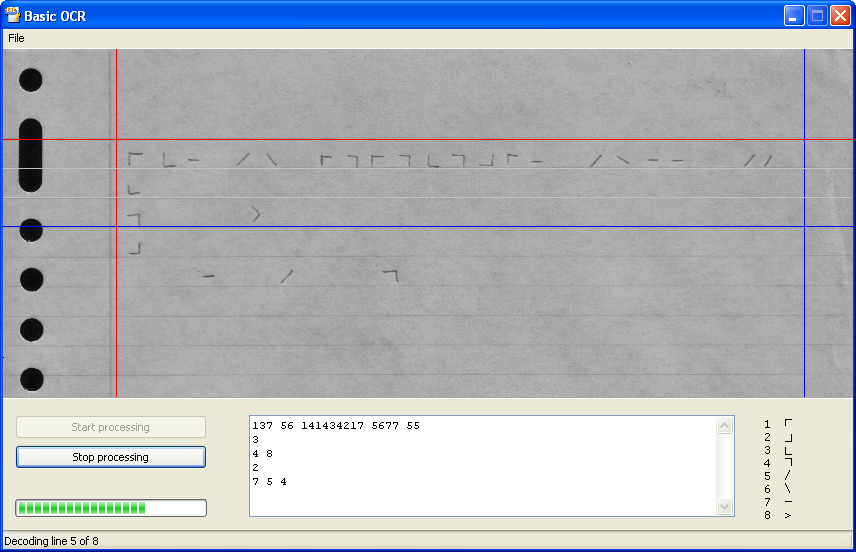
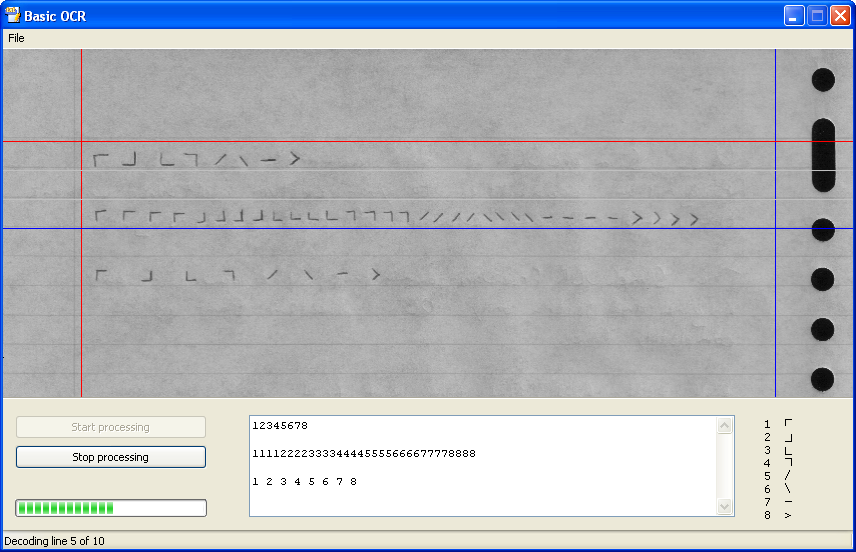
Toen ik na ging denken waarom bestaande OCR applicaties niet goed werken, kwam ik tot de conclusie dat dit is omdat er véél te veel tekens zijn die moeten worden herkend. Niet alleen alle 26 letters van het alfabet moeten gelezen worden, maar ook toevoegingen zoals é, è, ê en ë. Om dit allemaal te voorkomen in mijn OCR engine, heb ik besloten maar een beperkt aantal tekens te gebruiken, acht in totaal. Door deze tekens te vertalen naar getallen zodra ze zijn ingescand, is het daarna mogelijk om per combinatie van twee tekens (elk teken is overigens met één penbeweging op papier te zetten) er een letter of cijfer aan toe te wijzen. Op die manier kan je dus met 8 simpele tekens 64 verschillende letters en cijfers schrijven. Omdat er ook maar acht tekens gebruikt worden die zeer van elkaar verschillen, is er een herkenningsratio van 100%!